
Ilmuwan UCLA Mengembangkan Perangkat AI yang Memungkinkan Orang Berbicara Tanpa Pita Suara
By NV | 19 Juni 2024
Perkembangan teknologi di dunia saat ini terus mengalami kemajuan dan berkembang. Beberapa inovasi yang dilakukan para ilmuwan di seluruh dunia telah membawa banyak wawasan baru yang memudahkan kehidupan manusia sehari-hari.
Sekelompok insinyur di Universitas California, Los Angeles (UCLA) berhasil mengembangkan perangkat berbasis kecerdasan buatan (AI). Perangkat ini dapat membantu Anda berbicara tanpa menggunakan pita suara.
Dalam penelitian yang terbit di jurnal Nature Communications, perangkat bioelektrik ini dirancang untuk membantu orang-orang yang sering merasa kesulitan atau tidak mungkin berbicara. Misalnya saja orang dengan gangguan suara, seperti mereka yang menderita penyakit patologis pada pita suara atau mereka yang baru pulih dari operasi kanker laring.
Menggunakan teknologi AI, perangkat ini mampu mengenali gerakan otot mana yang sesuai dengan kata-kata tertentu. Sehingga, alat ini dapat berfungsi sebagai alat non-invasif bagi orang-orang yang kehilangan kemampuan berbicara karena masalah pita suara atau semacamnya.
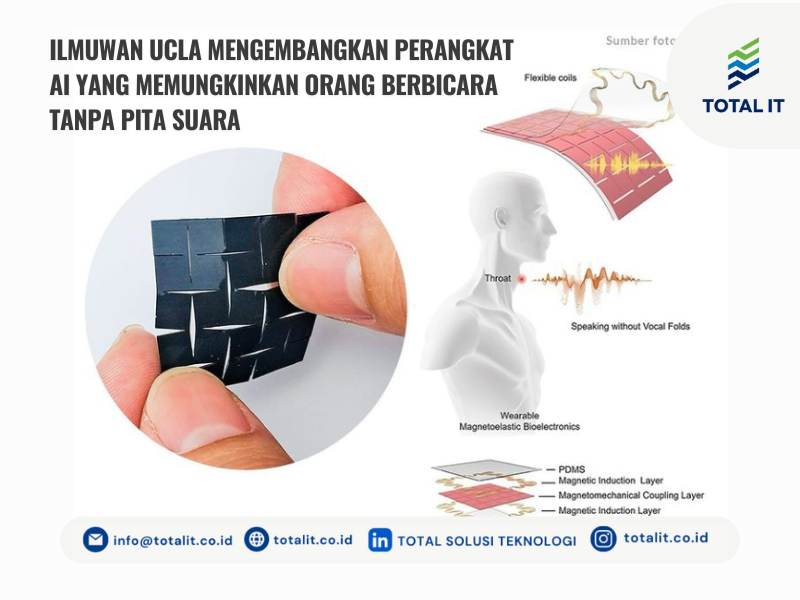
Melansir dari website resmi UCLA, para ahli bioteknologi UCLA menemukan perangkat tipis dan fleksibel berukuran lebih dari 1 inci yang dapat dipasang di daerah kulit leher, berfungsi untuk menerjemahkan gerakan otot laring menjadi ucapan yang dapat didengar.
Para peneliti mengatakan alat tersebut dapat membantu penderita disfungsi pita suara mendapatkan kembali fungsi suaranya. Untuk menggunakannya, terdapat selotip biokompatibel dua sisi. Selotip ini dapat dengan mudah ditempelkan pada tenggorokan seseorang di dekat pita suara dan dapat digunakan kembali dengan menempelkan kembali selotip tersebut sesuai kebutuhan.
Bagaimana para ilmuwan membuat perangkat?
Asisten Profesor Bioteknologi UCLA Samueli School of Engineering, Jun Chen dan rekan-rekannya mengembangkan sistem bioelektrik baru ini.
Dengan menggunakan teknologi pembelajaran mesin, sistem ini dapat mendeteksi pergerakan otot laring seseorang dan mengubah sinyal tersebut menjadi ucapan yang dapat didengar dengan akurasi hampir 95%.
Perangkat inovatif dan ringkas ini terdiri dari dua elemen utama: komponen penginderaan mandiri dan komponen aktuasi. Berikut penjelasannya sebagaimana dikutip dari laman resmi UCLA.
1. Komponen Penginderaan
Komponen ini bersifat mandiri energi dan dapat mendeteksi sinyal yang dihasilkan oleh gerakan otot dan mengubahnya menjadi sinyal listrik dengan presisi tinggi untuk dianalisis. Sinyal listrik ini diubah menjadi sinyal audio menggunakan algoritma pembelajaran mesin.
2. Komponen Aktuasi
Komponen ini mengubah sinyal audio menjadi representasi audio yang diinginkan. Kedua komponen tersebut masing-masing mengandung dua lapisan: lapisan yang terbuat dari polidimetilsiloksan (PDMS), senyawa silikon biokompatibel dengan sifat elastis, dan lapisan induksi magnetik yang terbuat dari kumparan induksi tembaga.
Dengan menggunakan mekanisme penginderaan magnetoelastik lembut, perangkat ini dapat mendeteksi perubahan medan magnet bila diubah oleh gaya mekanis.
Kumparan induksi serpentin yang tertanam dalam lapisan magnetoelastik berguna dalam menghasilkan sinyal listrik berkualitas tinggi untuk tujuan penginderaan.
"Perangkat baru ini menghadirkan opsi non-invasif yang dapat dipakai dan mampu membantu pasien berkomunikasi selama periode sebelum pengobatan dan selama masa pemulihan pasca perawatan untuk gangguan suara," ucap Chen, yang memimpin Wearable Bioelectronics Research Group di UCLA.
Hasil Uji Perangkat
Untuk mengukur akurasi, peneliti menguji teknologi terbaru pada delapan orang dewasa sehat. Para peneliti mengumpulkan data pergerakan otot di laring dan menggunakan algoritma pembelajaran mesin untuk mengaitkan sinyal yang dihasilkan dengan kata-kata tertentu. Kemudian pilih sinyal nada keluaran yang sesuai menggunakan komponen aktuasi perangkat.
Para peneliti mendemonstrasikan keakuratan sistem dengan meminta peserta mengucapkan lima kalimat dengan lantang dan tanpa suara, termasuk "Hai, Rachel, apa kabarmu hari ini?" dan "Aku mencintaimu!"
Hasilnya, akurasi prediksi model secara keseluruhan adalah 94,68%, dengan sinyal suara peserta diperkuat oleh komponen aktuasi. Ini menunjukkan bahwa mekanisme penginderaan mengenali sinyal gerakan laring mereka dan mencocokkan kalimat yang ingin diucapkan peserta.
Ke depannya, tim peneliti berencana menggunakan pembelajaran mesin untuk lebih memperluas kosakata perangkat dan mengujinya dengan orang-orang dengan gangguan bahasa.